

Hallucinations are a continuing and inevitable problem for LLMs because they are a byproduct of operation rather than a bug in design. But what if we knew when and why they happen?
“Hallucinations – the generation of plausible but false, fabricated, or nonsensical content – are not just common, they are mathematically unavoidable in all computable LLMs… hallucinations are not bugs, they are inevitable byproducts of how LLMs are built, and for enterprise applications, that’s a death knell,” wrote Srini Pagidyala(co-founder of Aigo AI) on LinkedIn.
Neil Johnson (professor of physics at GWU), goes further, “More worrying,” he says, “is that output can mysteriously tip mid-response from good (correct) to bad (misleading or wrong) without the user noticing.”
The use of AI is a trust / risk balance. Its benefits to cybersecurity cannot be ignored, but there is always the potential for the response to be wrong. Johnson is trying to add predictability to the unpredictable hallucination with the help of mathematics. His latest paper (Multispin Physics of AI Tipping Points and Hallucinations) extends arguments expressed in an earlier paper.
“Establishing a mathematical mapping to a multispin thermal system, we reveal a hidden tipping instability at the scale of the AI’s ‘atom’ (basic Attention head),” he writes. That tipping is the point at which the mathematical inevitability becomes the practical reality. His work will not eliminate hallucinations but could add visibility and potentially reduce the incidence of hallucinations in the future.
Given the increasing use of AI and the tendency to believe AI output above human expertise, “Harms and lawsuits from unnoticed good-to-bad output tipping look set to skyrocket globally across medical, mental health, financial, commercial, government and military AI domains.”
His solution is to “derive a simple formula that reveals, explains and predicts its output tipping, as well as the impact of the user’s prompt choice and training bias.”
The basis is a multispin thermal system, which is a concept from theoretical physics. A ‘spin’ is the quantum property or state of a particle. A multispin system models how a collection of these particles interact with each other. A thermal system adds ‘heat’ to the process, causing individual ’spins’ to flip their state in a binary fashion.
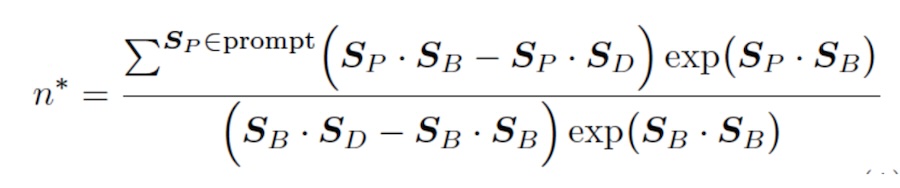
Johnson established a mathematical equivalence between gen-AI’s Attention engine and a multispin thermal system. The spins equate to the AI’s tokens; the thermal element equates to the degree of randomness built into the Attention engine, and the interactions involved correspond to how the tokens affect each other.
The resulting model allowed Johnson to develop a formula able to predict the point at which the token/spins become unstable and result in hallucinations.
Simple is a relative word, but the formula demonstrates the tipping point to D (bad token; that is, hallucination) type output given an initial prompt P1 P2 etc., will occur immediately after this number of B (good token; that is, correct) outputs.
If Johnson is correct, this knowledge won’t stop hallucinations, but could help AI designers reduce their incidence by being aware of the tipping point, and could theoretically help users know when one occurs. “This is different from most of the hallucination detection / fixing approaches which require the response to be complete before you can evaluate it,” comments Brad Micklea (CEO and co-founder of Jozu. “For example, Uncertainty Quantification is well proven (~80% success rate), but it cannot run until the response is generated.”
If Johnson’s formula is correct however, LLMs could be built to monitor their own responses in real time and stop bad responses as they are happening. Implementation would be tricky, demanding increased compute power and decreased response times – and that might not suit the foundation models’ business plans.
Diana Kelley (CISO at Noma Security) notes that OpenAI’s own research shows improved performance comes at the cost of increased hallucinations: GPT o3 hallucinated in a third of the benchmark tests while GPT o4 did so in almost half of them. It is difficult to see the foundation models reducing performance and increasing costs in future models.
“It might be more valuable, though,” adds Micklea, “for self-hosted models where the risks of hallucinations justify the added cost, such as medical or defense applications.”
Johnson believes two new design strategies suggested by his research could improve model performance in the future. The first he calls ‘gap cooling’: “Increase the gap between the top two pairs of interactions when they become too close (that is, just before tipping).”
The second he calls ’temperature annealing’: “Control the temperature dial T′ to balance between the risks of output tipping and excessive output randomness.”
“If we could predict when AI models might start giving unreliable responses – like when they’re close to ‘tipping points’ or more likely to hallucinate – it would be a game changer for keeping digital conversations safe and accurate. Automated tools that can spot these moments in real-time would help users trust what they see or read, knowing there’s an extra layer of detection watching out for sketchy responses before any harm is done,” says J Stephen Kowski (field CISO at SlashNext. “Having tech that flags risky AI behavior empowers people to make smarter choices online and stops threats before they turn into real headaches. That’s the kind of protection everyone should expect as AI gets even smarter.”
However, Johnson’s work remains theory. It looks promising, but nobody should expect any dramatic elimination or even reduction of hallucinations in the immediate future. “Bottom line,” comments John Allen (SVP and field CISO at Darktrace): “While theoretically intriguing, organizations shouldn’t expect immediate practical applications – but this could help inform future model development approaches.”
Learn About AI Hallucinations at the AI Risk Summit | Ritz-Carlton, Half Moon Bay
Related: AI Hallucinations Create a New Software Supply Chain Threat
Related: ChatGPT Hallucinations Can Be Exploited to Distribute Malicious Code Packages
Related: Epic AI Fails And What We Can Learn From Them
Related: AI Hallucinated Packages Fool Unsuspecting Developers